Node.js 메모리 누수를 발견하는 것은 꽤 어려울 수 있습니다.
고객의 마이크로 서비스 중 하나가 다음 메모리 사용량을 산출하기 시작했습니다.
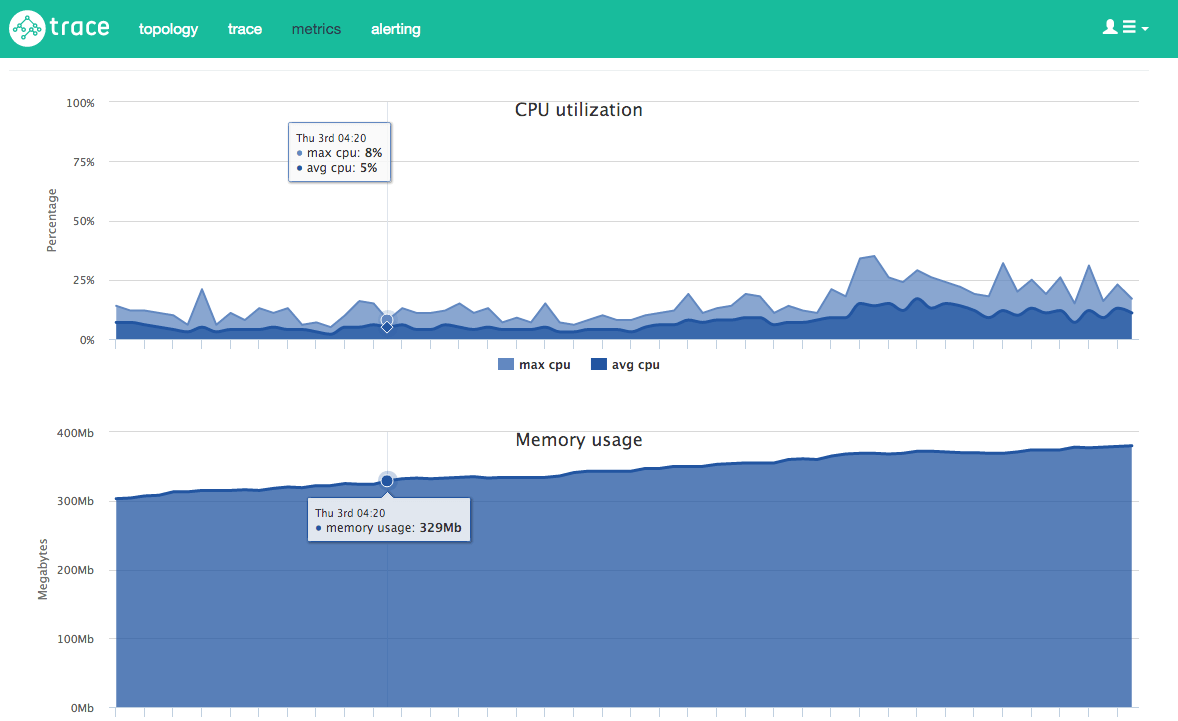
메모리 사용량을 추적으로 잡았습니다.
다음과 같은 일에 며칠을 보낼 수 있습니다 : 응용 프로그램을 프로파일 링하고 근본 원인을 찾으십시오. 이 글에서는 사용할 수있는 도구와 방법을 요약하여 알려 드리겠습니다.
TL 버전, DR 버전
우리의 특별한 경우에는 서비스가 512MB의 메모리만으로 작은 인스턴스에서 실행되고있었습니다. 결과적으로 응용 프로그램에서 메모리가 누출되지 않았으므로 GC가 참조되지 않은 객체를 수집하기 시작하지 않았습니다.
왜 그런 일이 일어 났습니까? 기본적으로 Node.js는 약 1.5GB의 메모리를 사용하려고합니다.이 메모리는 메모리가 적은 시스템에서 실행될 때 제한되어야합니다. 이것은 가비지 수집이 매우 비용이 많이 드는 작업이므로 예상되는 동작입니다.
그 해결책은 Node.js 프로세스에 추가 매개 변수를 추가하는 것입니다.
node --max_old_space_size=400 server.js --production
* 여전히 명확하지 않은 경우 메모리 누수를 찾기위한 옵션은 무엇입니까? * The React.js Way : Getting Started Tutorial
V8의 메모리 처리에 대한 이해
Node.js 애플리케이션에서 메모리 누수를 찾아서 해결할 수있는 기술을 배우기 전에 V8에서 메모리가 어떻게 처리되는지 살펴 보겠습니다.
정의
- 상주 세트 크기 : RAM에 보유 된 프로세스가 차지하는 메모리의 부분이며, 여기에는 다음이 포함됩니다.
- 코드 자체
- 스택
- 힙
- stack : 기본 유형과 객체에 대한 참조를 포함합니다.
- 힙 : 객체, 문자열 또는 클로저와 같은 참조 유형을 저장합니다.
- 객체의 얕은 크기 : 객체 자체가 보유하는 메모리의 크기
- 유지 된 객체 크기 : 객체가 '종속 객체'와 함께 삭제되면 해제되는 메모리의 크기
가비지 수집기 작동 방법
가비지 콜렉션은 응용 프로그램이 더 이상 사용하지 않는 오브젝트가 차지하는 메모리를 교정하는 프로세스입니다. 일반적으로 메모리 할당은 저렴하지만 메모리 풀이 고갈되면 수집하는 데 많은 비용이 듭니다.
루트 노드에서 도달 할 수 없으면 루트 객체 나 다른 활성 객체에 의해 참조되지 않을 때 객체는 가비지 컬렉션의 후보입니다. 루트 객체는 전역 객체, DOM 요소 또는 로컬 변수가 될 수 있습니다.
힙에는 두 개의 주요 세그먼트 인 New Space 와 Old Space가 있습니다. 새로운 공간은 새로운 할당이 일어나는 곳입니다. 여기에 쓰레기를 모으는 것이 빠르며 ~ 1-8MB 크기입니다. 새로운 공간에 살고있는 대상을 젊은 세대 라고 합니다. 올드 스페이스 (Old Space)는 뉴 스페이스 (New Space)에서 콜렉터에서 살아남은 오브젝트가 승격되는 곳으로, 올드 세대 (Old Generation) 라고 부릅니다 . Old Space에서의 할당은 빠르지 만 콜렉션이 비싸기 때문에 드물게 수행됩니다.
왜 가비지 콜렉션이 비쌉니까? V8 JavaScript 엔진은 전 세계 가비지 수집기 메커니즘을 사용합니다. 실제로는 가비지 수집이 진행되는 동안 프로그램이 실행을 중지한다는 것을 의미합니다.
보통, 젊은 세대의 ~ 20 %는 구세대에 살아남습니다. 구식 공간에서의 수집은 일단 소진되면 시작됩니다. 이렇게하기 위해 V8 엔진은 두 가지 다른 수집 알고리즘을 사용합니다 :
- 빠른 속도로 젊은 세대에서 운영되는 청소 수집 (Scavenge collection)
- Mark-Sweep 콜렉션은 느리고 오래되어서 사용됩니다.
이 작업 방법에 대한 자세한 내용 은 V8 둘러보기 : 가비지 수집 문서를 확인하십시오. 일반 메모리 관리에 대한 자세한 내용은 메모리 관리 참조를 참조하십시오 .
Node.js에서 메모리 누수를 찾을 때 사용할 수있는 도구 / 기법
힙 덤프 모듈
heapdump모듈을 사용하면 나중에 검사 할 수 있도록 힙 스냅 샷을 생성 할 수 있습니다. 프로젝트에 추가하는 것은 다음과 같이 쉽습니다.
npm install heapdump --save
그런 다음 엔트리 포인트에 다음을 추가하십시오.
var heapdump = require('heapdump');
작업이 끝나면 명령을 사용하거나 다음을 호출 heapdump하여 수집 을 시작할 수 있습니다 $ kill -USR2 <pid>.
heapdump.writeSnapshot(function(err, filename) {
console.log('dump written to', filename);
});
스냅 샷을 얻은 후에는 스냅 샷을 이해할 시간입니다. 당신이 그들을 비교할 수 있도록 약간의 시간차를 가지고 여러개를 캡처해야합니다.
Google Chrome DevTools
먼저 메모리 스냅 샷을 Chrome 프로필러에로드해야합니다. 그렇게하려면 Chrome DevTools를 열고 프로필로 이동 하여 힙 스냅 샷을 로드 하십시오.

일단로드하면 다음과 같이됩니다.

지금까지는 그렇게 좋았지 만이 스크린 샷에서 정확히 무엇을 볼 수 있습니까?
여기서 주목해야 할 가장 중요한 사항 중 하나는 선택한보기 : 비교 입니다. 이 모드를 사용하면 서로 다른 시간에 찍은 두 개 이상의 힙 스냅 샷 을 비교할 수 있으므로 그 동안 할당 된 오브젝트와 해제되지 않은 오브젝트를 정확히 찾아 낼 수 있습니다.
다른 중요한 탭은 Retainers 입니다. 그것은 왜 객체가 가비지 수집 될 수 없는지, 그 객체에 대한 참조를 보유하고 있는지를 정확하게 보여줍니다. 이 경우 호출 된 전역 변수 log가 가비지 수집기가 공간을 확보 할 수 없도록 객체 자체에 대한 참조를 보유합니다.
낮은 수준의 도구
mdb
mdb 유틸리티는 라이브 운영 체제, 운영 체제 크래시 덤프, 사용자 프로세스, 사용자 프로세스 코어 덤프 및 오브젝트 파일의 저수준 디버깅 및 편집을위한 확장 유틸리티입니다.
gcore
프로세스 ID가 pid 인 실행중인 프로그램의 코어 덤프를 생성하십시오.
함께 모으기
덤프를 조사하려면 먼저 덤프를 만들어야합니다. 다음과 같이 쉽게 할 수 있습니다.
gcore `pgrep node`
일단 가지고 있다면, 다음을 사용하여 힙에있는 모든 JS 객체를 검색 할 수 있습니다.
> ::findjsobjects
물론 여러 덤프를 비교할 수 있도록 연속 코어 덤프를 가져와야합니다.
의심스러운 것으로 보이는 개체를 식별하면 다음을 사용하여 개체를 분석 할 수 있습니다.
object_id::jsprint
이제는 객체의 고정자 (루트)를 찾는 것뿐입니다.
object_id::findjsobjects -r
이 명령은 id리테이너 와 함께 복귀 합니다. 그런 다음 ::jsprint리테이너를 분석하기 위해 다시 사용할 수 있습니다 .
Netflix에서 Yunong Xiao의 사용 방법에 대한 자세한 버전을 확인하려면 다음을 참조하십시오.
'개발 > Node.JS' 카테고리의 다른 글
| 사례 연구 : Ghost에서 Node.js 메모리 누수 찾기 (0) | 2018.03.11 |
|---|---|
| JavaScript 가비지 콜렉션 개선 (0) | 2018.03.11 |
| Node.js Internals Deep Dive - 네이티브 Node.js 모듈 작성하기 (0) | 2018.03.11 |
| Node.js Internals Deep Dive - Node.js 가비지 컬렉션 설명 (0) | 2018.03.11 |
| npm - CommonJS & require가 작동하는 방식 (0) | 2018.03.11 |