
V8 자바 스크립트 엔진
JS에서 DOM으로 추적하고 다시 추적
개요
Chrome에서 메모리 누수를 디버깅하는 것은 훨씬 쉬워졌습니다. Chrome의 DevTools는 이제 C ++ DOM 객체를 추적하고 스냅 샷을 작성하고 JavaScript를 통해 참조 가능한 모든 DOM 객체를 표시합니다. 이 기능은 V8 가비지 수집기의 새로운 C ++ 추적 메커니즘의 이점 중 하나입니다.
배경
가비지 콜렉션 시스템에서의 메모리 누수는 다른 오브젝트로부터 의도하지 않은 참조로 인해 사용되지 않은 오브젝트가 해제되지 않은 경우 발생합니다. 웹 페이지의 메모리 누출은 종종 JavaScript 객체와 DOM 요소 간의 상호 작용을 수반합니다.
다음 장난감 예 는 프로그래머가 이벤트 리스너의 등록을 잊어 버렸을 때 발생하는 메모리 누수를 보여줍니다. 이벤트 리스너가 참조하는 객체는 가비지 수집 될 수 없습니다. 특히, iframe 창은 이벤트 리스너와 함께 누출됩니다.
// Main window:
const iframe = document.createElement('iframe');
iframe.src = 'iframe.html';
document.body.appendChild(iframe);
iframe.addEventListener('load', function() {
const local_variable = iframe.contentWindow;
function leakingListener() {
// Do something with `local_variable`.
if (local_variable) {}
}
document.body.addEventListener('my-debug-event', leakingListener);
document.body.removeChild(iframe);
// BUG: forgot to unregister `leakingListener`.
});
누출 iframe 창은 또한 모든 JavaScript 객체를 유지합니다.
// iframe.html:
class Leak {};
window.global_variable = new Leak();
메모리 누수의 근본 원인을 찾기 위해 경로를 유지한다는 개념을 이해하는 것이 중요합니다. 보관 경로는 누출 된 개체의 가비지 수집을 방지하는 개체 체인입니다. 체인은 기본 창의 전역 개체와 같은 루트 개체에서 시작됩니다. 체인이 새는 물체에서 끝납니다. 체인의 각 중간 객체는 체인의 다음 객체를 직접 참조합니다. 예를 들어 Leakiframe 에있는 객체의 보관 경로는 다음과 같습니다.
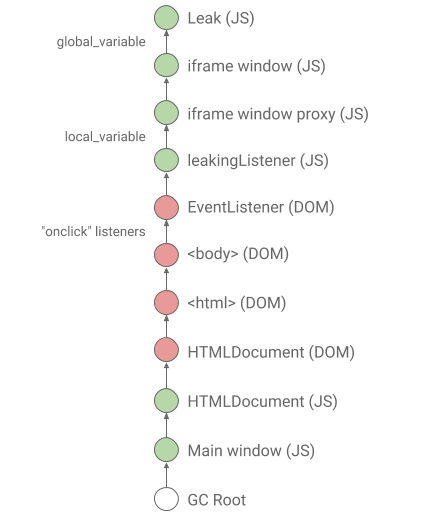 |
| 그림 1 : iframe 및 이벤트 리스너를 통해 유출 된 객체의 경로 유지. |
유지 경로는 JavaScript / DOM 경계 (녹색 / 빨간색으로 각각 강조 표시됨)를 두 번 교차합니다. 자바 스크립트 개체는 V8 힙에 저장되지만 DOM 개체는 Chrome의 C ++ 개체입니다.
DevTools 힙 스냅 샷
DevTools에서 힙 스냅 샷을 찍어 개체의 유지 경로를 검사 할 수 있습니다. 힙 스냅 샷은 V8 힙의 모든 오브젝트를 정확하게 캡처합니다. 최근까지는 C ++ DOM 객체에 대한 대략적인 정보 만있었습니다. 예를 들어 Chrome 65에서는 Leak장난감 예의 개체 가 불완전하게 유지되는 경로를 보여줍니다 .
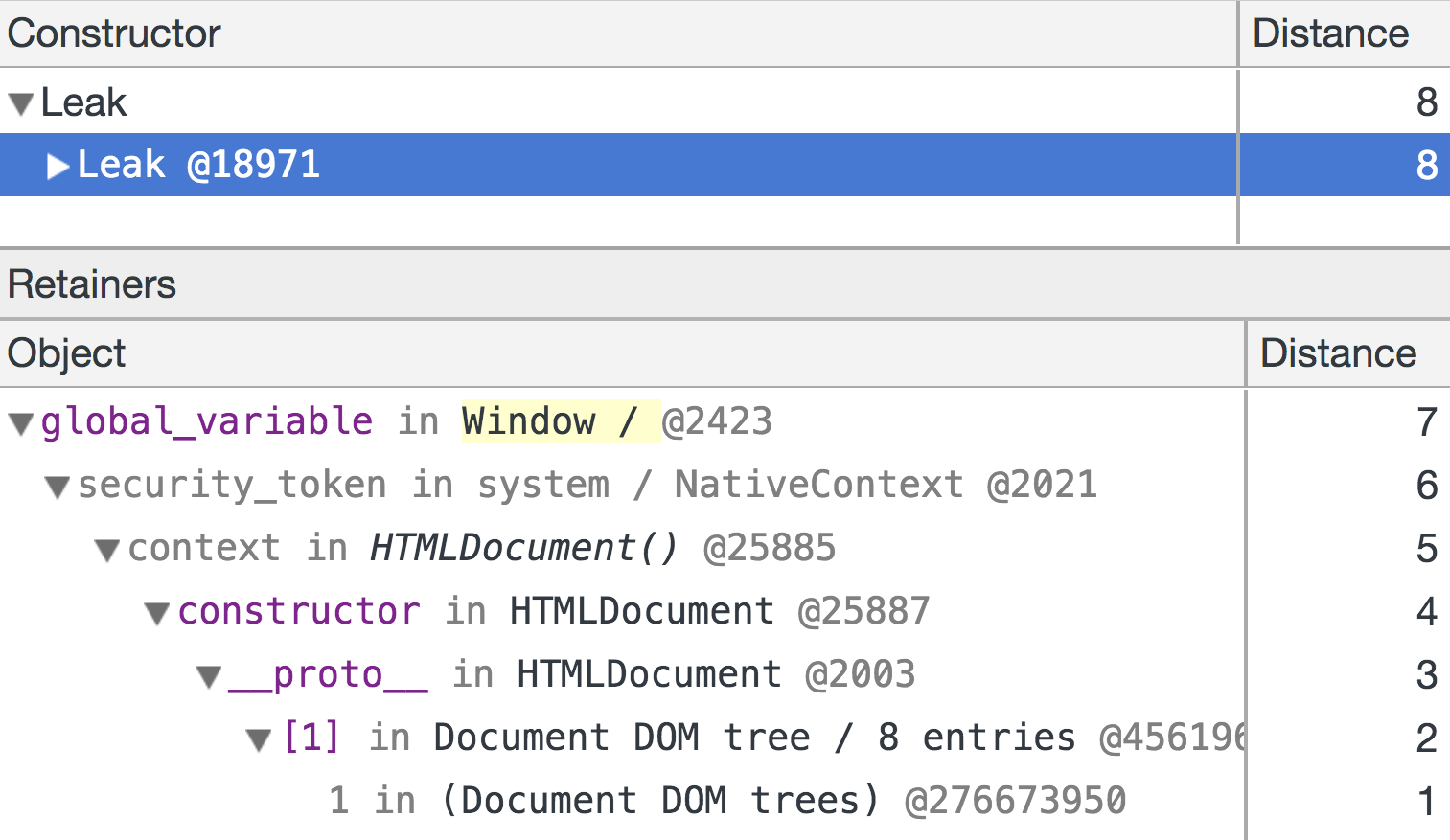 |
| 그림 2 : Chrome에서 경로 유지 65. |
첫 번째 행만 정확합니다. Leak객체는 실제로 global_variableiframe의 window 객체에 저장됩니다 . 후속 행은 실제 유지 경로를 근사하고 메모리 누수의 디버깅을 어렵게 만듭니다.
Chrome 66부터 DevTools는 C ++ DOM 개체를 추적하고 개체 간의 참조를 정확하게 캡처합니다. 이는 이전에 교차 컴포넌트 가비지 콜렉션에 도입 된 강력한 C ++ 오브젝트 추적 메커니즘을 기반으로합니다. 결과적으로 DevTools의 유지 경로 가 실제로 올바른 것입니다.
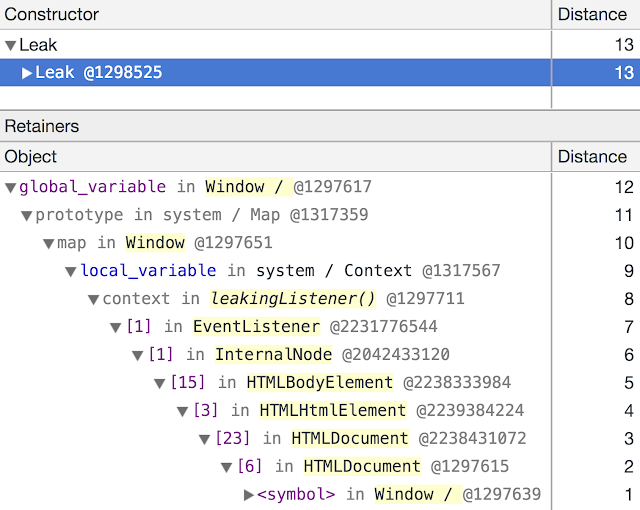 |
| 그림 3 : Chrome에서 경로 유지 66 |
후드 : 교차 구성 요소 추적
DOM 개체는 화면의 실제 텍스트와 이미지로 DOM을 변환하는 역할을하는 Chrome의 렌더링 엔진 인 Blink에서 관리합니다. Blink와 DOM 표현은 C ++로 작성되었으므로 DOM을 JavaScript에 직접 노출 할 수 없습니다. 대신 DOM의 객체는 두 가지로 나뉩니다. 하나는 JavaScript에서 사용할 수있는 V8 래퍼 객체이고 다른 하나는 DOM에서 노드를 나타내는 C ++ 객체입니다. 이러한 객체는 서로 직접 참조됩니다. Blink 및 V8과 같은 여러 구성 요소에서 개체의 생명 및 소유권을 결정하는 것은 어려운 일입니다. 모든 관련 당사자가 어떤 개체가 아직 살아 있고 어떤 개체가 재생 될 수 있는지에 대해 동의해야하기 때문입니다.
Chrome 56 이하 버전 (즉, 2017 년 3 월까지)에서 Chrome은 객체 그룹화 라는 메커니즘을 사용했습니다.생기를 결정하기. 개체는 문서의 봉쇄를 기반으로 그룹에 할당되었습니다. 모든 객체를 포함하는 그룹은 단일 객체가 다른 유지 경로를 통해 활성 상태로 유지되는 한 활성 상태를 유지했습니다. 이것은 소위 DOM 트리를 형성하면서 DOM 노드가 포함 된 문서를 항상 참조하는 DOM 노드의 맥락에서 의미가 있습니다. 그러나이 추상화는 실제 유지 경로를 모두 제거 했으므로 그림 2와 같이 디버깅에 사용하기가 어려웠습니다.이 시나리오에 맞지 않는 객체의 경우 (예 : JavaScript가 이벤트 리스너로 사용됨)이 방법도 번거로워졌습니다 JavaScript 래퍼 객체가 조기에 수집되어 다양한 속성을 잃을 빈 JS 래퍼로 바뀌는 다양한 버그가 발생했습니다.
Chrome 57부터는이 접근 방식이 크로스 컴포넌트 추적 (cross-component tracing)으로 대체되었습니다.이 추적은 JavaScript에서 DOM의 C ++ 구현을 추적하여 생동감을 결정하는 메커니즘입니다. 우리는 C ++ 측에서 점진적인 추적을 구현하여 이전 장의 블로그 게시물 에서 이야기했던 모든 세계를 멈추지 않게했습니다 . 교차 구성 요소 추적은 더 나은 대기 시간을 제공 할뿐만 아니라 구성 요소 경계를 넘나 드는 개체의 활성도를 대략적으로 추정하고 누출을 유발하는 여러 시나리오 를 수정 합니다. 또한 DevTools는 그림 3과 같이 DOM을 실제로 나타내는 스냅 샷을 제공 할 수 있습니다.
2018 년 2 월 12 일 월요일
지연 직렬화
TL : DR의 직렬화가 V8 버전 6.4 에서 기본적으로 활성화되어 브라우저 탭당 V8 메모리 사용량이 평균 500KB 이상 줄어 들었습니다. 자세한 내용은 계속 읽으십시오!
V8 스냅 샷 소개
하지만 먼저 단계별로 살펴보고 V8에서 힙 스냅 샷을 사용하여 새로운 분리 생성 (Chrome의 브라우저 탭에 해당) 생성 속도를 높이는 방법을 살펴 보겠습니다. 동료 인 양 구오 (Guo Guo)는 맞춤 시작 스냅 샷 에 대한 기사에서 앞 부분에 대한 좋은 소개를했습니다 .
자바 스크립트 사양에는 수학 기능에서 완전한 기능을 갖춘 정규 표현 엔진에 이르기까지 다양한 내장 기능이 포함되어 있습니다. 새로 생성 된 모든 V8 컨텍스트에는 처음부터 사용할 수있는 이러한 기능이 있습니다. 이 기능을 사용하려면 전역 객체 (예
window: 브라우저 의 객체)와 모든 내장 기능을 설정하고 컨텍스트를 만들 때 V8의 힙으로 초기화해야합니다. 처음부터이 작업을 수행하는 데는 상당한 시간이 걸립니다.다행히도 V8은 단축키를 사용하여 작업 속도를 향상시킵니다. 즉, 빠른 저녁 식사를 위해 고정 된 피자를 해동하는 것과 마찬가지로 초기화 된 컨텍스트를 얻기 위해 미리 준비된 스냅 샷을 힙으로 직접 deserialize합니다. 일반 데스크탑 컴퓨터에서는 40ms에서 2ms 미만의 컨텍스트를 생성 할 수 있습니다. 평균적인 휴대 전화에서는 270ms에서 10ms 사이의 차이를 의미 할 수 있습니다.
요약하면 : 스냅 샷은 시작 성능에 중요하며 각 스냅 샷에 대한 V8 힙의 초기 상태를 생성하기 위해 비 직렬화됩니다. 따라서 스냅 샷의 크기는 V8 힙의 최소 크기를 결정하고 더 큰 스냅 샷은 각 격리 지점에 대한 더 높은 메모리 소비로 직접 변환됩니다.
스냅 샷에는 언어 상수 (예 : undefined값), 인터프리터에서 사용하는 내부 바이트 코드 처리기, 내장 객체 (예 :) String및 내장 객체에 설치된 함수 (예 : 새 정수)를 포함하여 새 분리를 완전히 초기화하는 데 필요한 모든 것이 포함 되어 있습니다. , String.prototype.replace)를 실행 Code개체 와 함께 사용 합니다.
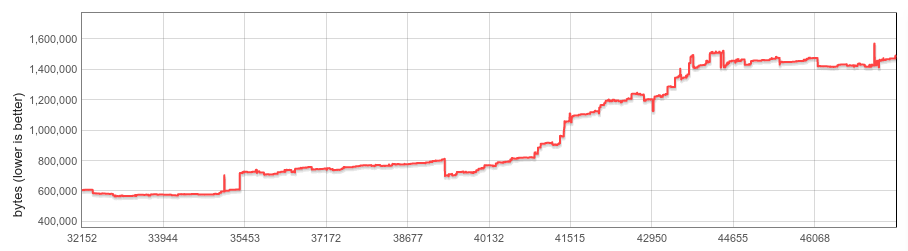 |
| 2016-01에서 2017-09까지의 시작 스냅 샷 크기 (바이트). X 축은 V8 개정 번호를 표시합니다. |
지난 2 년 동안 스냅 샷 크기는 거의 3 배 증가하여 2016 년 초 약 600KB에서 현재 1500KB 이상으로 증가했습니다. 이 증가의 대부분은 직렬화 된 Code객체 에서 비롯됩니다.이 객체는 카운트가 증가했습니다 (예 : 언어 사양이 발전하면서 최근에 추가 된 JavaScript 언어를 통해). 크기가 작 으면 (새 CodeStubAssembler 파이프 라인 에서 생성 된 기본 제공 코드는 네이티브 코드와 비교하여 압축 된 바이트 코드 또는 최소화 된 JS 형식으로 제공됩니다).
이것은 메모리 소비를 가능한 한 낮게 유지하고자하므로 나쁜 소식입니다.
지연 직렬화
주요 문제점 중 하나는 스냅 샷의 전체 내용을 각 격리 지점에 복사하는 것이 었습니다. 그렇게하는 것은 내장 함수에 대해 특히 낭비였습니다. 모든 함수는 무조건로드되었지만 결코 사용되지 않았을 수 있습니다.
여기서 게으른 비 직렬화가 시작됩니다. 개념은 간단합니다. 호출하기 직전에 내장 함수를 deserialize하려면 어떻게해야합니까?
가장 인기있는 웹 사이트에 대한 조사를 통해이 접근 방식이 매우 매력적 이었음을 알 수있었습니다. 평균적으로 모든 내장 기능 중 30 % 만 사용되었으며 일부 사이트는 16 % 만 사용했습니다. 이 사이트의 대부분은 무거운 JS 사용자이므로이 숫자는 웹 전반에 대한 잠재적 인 메모리 절약의 (퍼지) 하한으로 볼 수 있습니다.
우리가이 방향으로 작업을 시작했을 때, 게으른 비 직렬화가 V8의 아키텍처와 매우 잘 통합되었으며, 실행 및 실행에 필요한 비 침습적 디자인 변경 사항은 거의 없었습니다.
- 스냅 샷 내의 잘 알려진 위치. 지연 직렬화 이전에 직렬화 된 스냅 샷 내의 객체 순서는 관련성이 없었습니다. 전체 힙을 한 번에 deserialize하기 때문입니다. 지연 직렬화는 자체 내장 된 함수를 deserialize 할 수 있어야하므로 스냅 샷 내에있는 내장 된 함수를 deserialize 할 수 있어야합니다.
- 단일 객체의 비 직렬화. V8의 스냅 샷은 처음에는 완전한 힙 직렬화를 위해 설계되었으며, 단일 객체 직렬화 지원에 대한 지원은 불연속 스냅 샷 레이아웃 (한 객체의 직렬화 된 데이터가 다른 객체의 데이터와 함께 산재 될 수 있음)과 같은 몇 가지 단점을 처리하고, (현재 실행 내에서 이전에 비 직렬화 된 객체를 직접 참조 할 수있는) 소급 역 참조.
- 게으른 비 직렬화 메커니즘 자체. 런타임시 lazy deserialization 처리기는 a) 직렬화 할 코드 객체를 결정하고, b) 실제 deserialization을 수행하고, c) 직렬화 된 코드 객체를 모든 관련 함수에 첨부 할 수 있어야합니다.
첫 번째 두 가지 사항에 대한 우리의 솔루션 은 스냅 샷에 새로운 전용 내장 영역 을 추가하는 것이 었습니다.이 영역 에는 일련 화 된 코드 객체 만 포함될 수 있습니다. 직렬화는 잘 정의 된 순서로 발생하며 각 Code객체 의 시작 오프셋은 내장 스냅 샷 영역 내의 전용 섹션에 보관됩니다. 역 참조와 산재 된 오브젝트 데이터는 모두 허용되지 않습니다.
게으른 내장 비 직렬화 는 비 직렬화 시 모든 지연 내장 함수에 설치된 적절한 이름의 DeserializeLazy내장 함수에 의해 처리됩니다 . 런타임에 호출되면 관련 Code객체를 비 직렬화 한 다음 최종적으로 JSFunction(함수 객체를 나타내는) 및 SharedFunctionInfo(동일한 함수 리터럴에서 만든 함수간에 공유 합니다.) 둘 다에 설치합니다 . 각 기본 제공 함수는 한 번만 deserialize됩니다.
내장 함수 외에도 바이트 코드 처리기에 대한 지연 직렬화 (lazy deserialization) 도 구현했습니다 . 바이트 코드 처리기는 V8의 Ignition 인터프리터 에서 각 바이트 코드를 실행하는 논리를 포함하는 코드 객체입니다 . 빌트인과는 달리, 그들은 첨부 JSFunction도 아니다 SharedFunctionInfo. 그 대신, 코드 객체는 인터프리터가 다음 바이트 코드 처리기로 디스패치 할 때 색인을 생성 하는 디스패치 테이블 에 직접 저장됩니다 . 지연 직렬화는 내장 DeserializeLazy함수 와 비슷합니다. 핸들러는 바이트 코드 배열을 검사하여 비 직렬화 할 핸들러를 결정하고, 코드 객체를 deserialize하고, 디스 패칭 테이블에 deserialize 된 핸들러를 저장합니다. 다시 한번, 각 핸들러는 한 번만 deserialize됩니다.
결과
Google은 게으른 비 직렬화의 유무와 상관없이 Android 기기에서 Chrome 65를 사용하여 가장 인기있는 상위 1000 개 웹 사이트를로드하여 메모리 사용량을 평가했습니다.
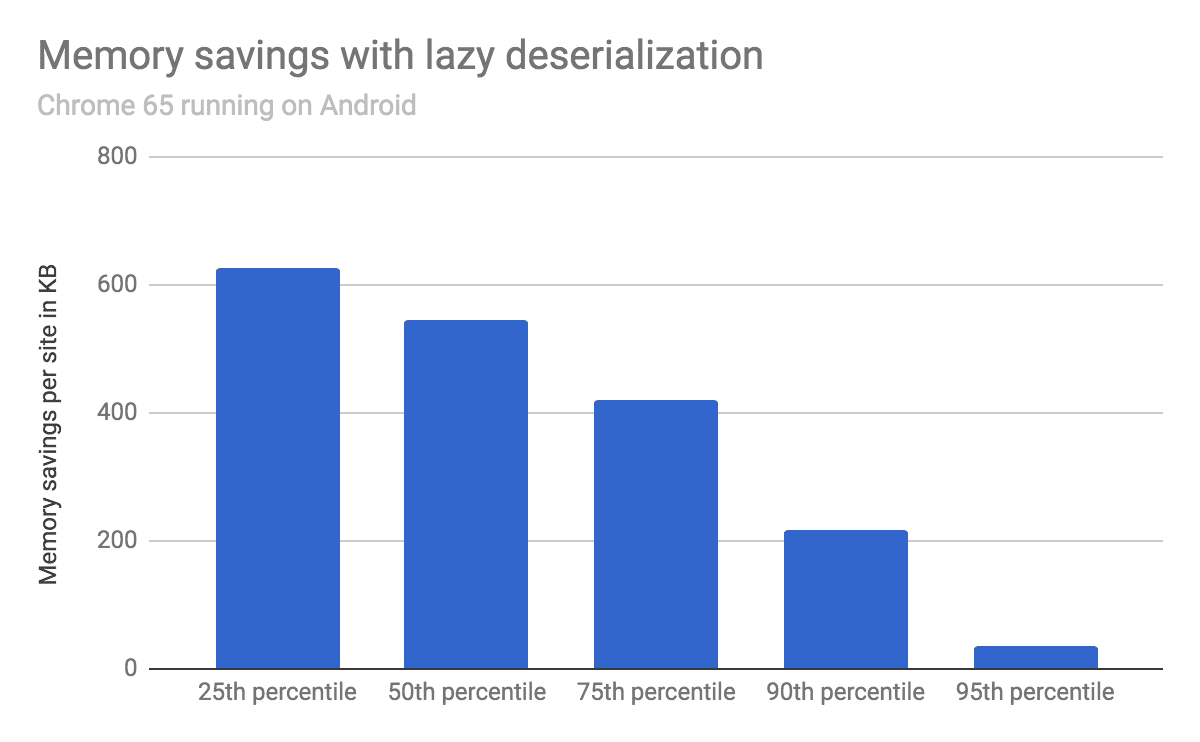
평균적으로 V8의 힙 크기는 540KB 감소했으며 테스트 된 사이트 중 25 %는 620KB 이상, 50 %는 540KB 이상, 75 %는 420KB 이상을 절약했습니다.
런타임 성능 (속도계와 같은 표준 JS 벤치 마크 및 널리 사용되는 다양한 웹 사이트에서 측정)은 지연 직렬화의 영향을받지 않습니다.
다음 단계
Lazy deserialization은 각 Isolate가 실제로 사용되는 내장 코드 객체 만로드하도록합니다. 이는 이미 큰 승리이지만 우리는 한 단계 더 나아가 각 개별 격리 항목의 비용을 효과적으로 0으로 줄이는 것이 가능하다고 믿습니다.
2018 년 2 월 1 일 목요일
V8 릴리스 v6.5
6 주마다 릴리스 프로세스의 일부로 V8의 새 지점을 만듭니다 . 각 버전은 Chrome 베타 마일스톤 직전에 V8의 Git 마스터에서 분기됩니다. 오늘 우리는 최신 분기 인 V8 버전 6.5 를 발표하게 된 것을 기쁘게 생각합니다. V8 버전 은 몇 주 안에 Chrome 65 Stable과 함께 출시 될 때까지 베타 버전입니다. V8 v6.5는 모든 종류의 개발자를위한 제품으로 가득 차 있습니다. 이 게시물은 출시를 예상하여 일부 하이라이트에 대한 미리보기를 제공합니다.
신뢰할 수없는 코드 모드
Spectre라는 최신의 투기 측 채널 공격에 대응하여 V8은 신뢰할 수없는 코드 모드를 도입했습니다 . V8을 내장 한 경우 애플리케이션에서 사용자가 생성 한 신뢰할 수없는 코드를 처리 할 때이 모드를 활용하는 것이 좋습니다. 이 모드는 Chrome을 포함하여 기본적으로 사용 설정되어 있습니다.
WebAssembly 코드의 스트리밍 컴파일
WebAssembly API는 fetch()API 와 함께 스트리밍 컴파일을 지원하는 특수 함수를 제공합니다 .
const module = await WebAssembly.compileStreaming(fetch('foo.wasm'));
초기 구현에서는 실제로 스트리밍 컴파일을 사용하지 않았지만이 API는 V8 v6.1 및 Chrome 61부터 사용할 수 있습니다. 그러나 V8 v6.5와 Chrome 65에서는 모듈 바이트를 다운로드하는 동안 이미이 API를 활용하고 WebAssembly 모듈을 컴파일합니다. 단일 함수의 모든 바이트를 다운로드하자마자 함수를 백그라운드 스레드에 전달하여 컴파일합니다.
측정 결과에 따르면이 API를 사용하면 Chrome 65의 WebAssembly 컴파일은 고급 컴퓨터에서 최대 50Mbps의 다운로드 속도를 유지할 수 있습니다. 즉, 50Mbit / 초로 WebAssembly 코드를 다운로드하면 다운로드가 완료 되 자마자 해당 코드의 컴파일이 완료됩니다.
아래의 그래프에서 우리는 67 MB 및 약 190,000 개의 기능을 가진 WebAssembly 모듈을 다운로드하고 컴파일하는 데 걸리는 시간을 측정합니다. 우리는 25 Mbit / sec, 50 Mbit / sec 및 100 Mbit / sec 다운로드 속도로 측정합니다.
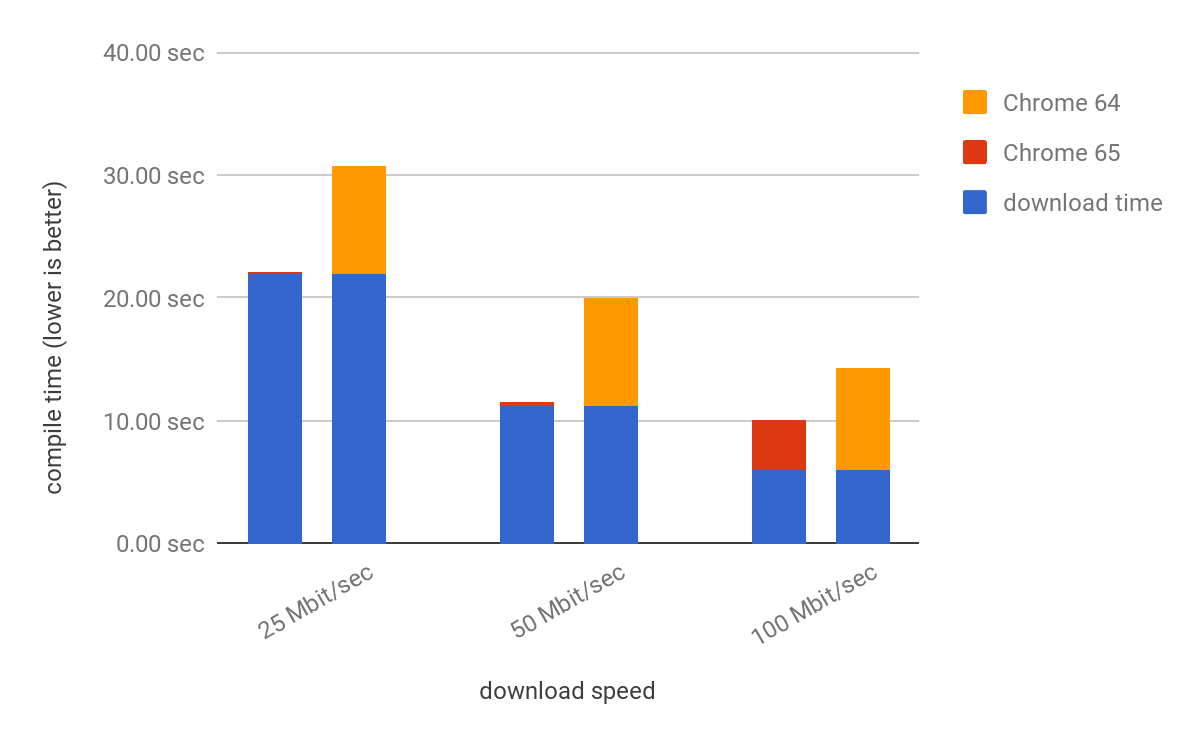
다운로드 시간이 WebAssembly 모듈의 컴파일 시간 (예 : 위의 그래프에서 25 Mbit / sec 및 50 Mbit / sec)보다 길면 WebAssembly.compileStreaming()마지막 바이트가 다운로드 된 직후 컴파일이 완료됩니다.
다운로드 시간이 컴파일 시간보다 짧으면 WebAssembly.compileStreaming()모듈을 먼저 다운로드하지 않고 WebAssembly 모듈을 컴파일하는 데 걸리는 시간이 소요됩니다.
속도
우리는 JavaScript 내장 함수의 빠른 경로를 넓히기 위해 지속적으로 노력했으며, "최적화 해제 루프"라고하는 파손 된 상황을 감지하고 방지하는 메커니즘을 추가했습니다. 이는 최적화 된 코드가 최적화 되지 않았을 때 발생하며, 틀렸다 . 이러한 시나리오에서 TurboFan은 최적화를 계속 시도하며 결국 약 30 회 시도를 포기합니다. 이것은 2 차 배열 내장 함수의 콜백 함수에서 배열의 모양을 변경하려는 작업을 수행 한 경우에 발생합니다. 예를 들어 lengthv6.5에서 배열을 변경 하면 그 시점을 알 수 있으며 향후 최적화 시도에서 해당 사이트에서 호출 된 내장 배열을 인라이닝하지 않습니다.
또한 함수 호출의로드와 호출 자체 (예 : 함수 호출) 간의 부작용으로 인해 이전에 제외 된 많은 내장 함수를 인라인함으로써 빠른 경로를 확대했습니다. 그리고 함수 호출에서 성능String.prototype.indexOf 이 10 배 향상되었습니다 .
V8의 V6.4에서, 우리는 지원을 인라인 것 Array.prototype.forEach, Array.prototype.map하고 Array.prototype.filter. V8 v6.5에서 다음에 대한 인라인 지원이 추가되었습니다.
Array.prototype.reduceArray.prototype.reduceRightArray.prototype.findArray.prototype.findIndexArray.prototype.someArray.prototype.every
또한, 우리는 이러한 모든 내장 된 제품의 빠른 경로를 확장했습니다. 처음에는 배열에 부동 소수점 숫자가있는 배열을 보거나 , 배열에 "구멍"이있는 경우 (더 많은 정보 를 얻을 수 있습니다 ) [3, 4.5, , 6]. 이제, 우리가 제외한 모든 구멍 투성이의 부동 소수점 배열을 처리 find하고 findIndex로 사양 요구 사항이 구멍을 변환 할 경우, undefined우리의 노력에 원숭이 렌치를 던졌습니다 ( 지금은 ...! ).
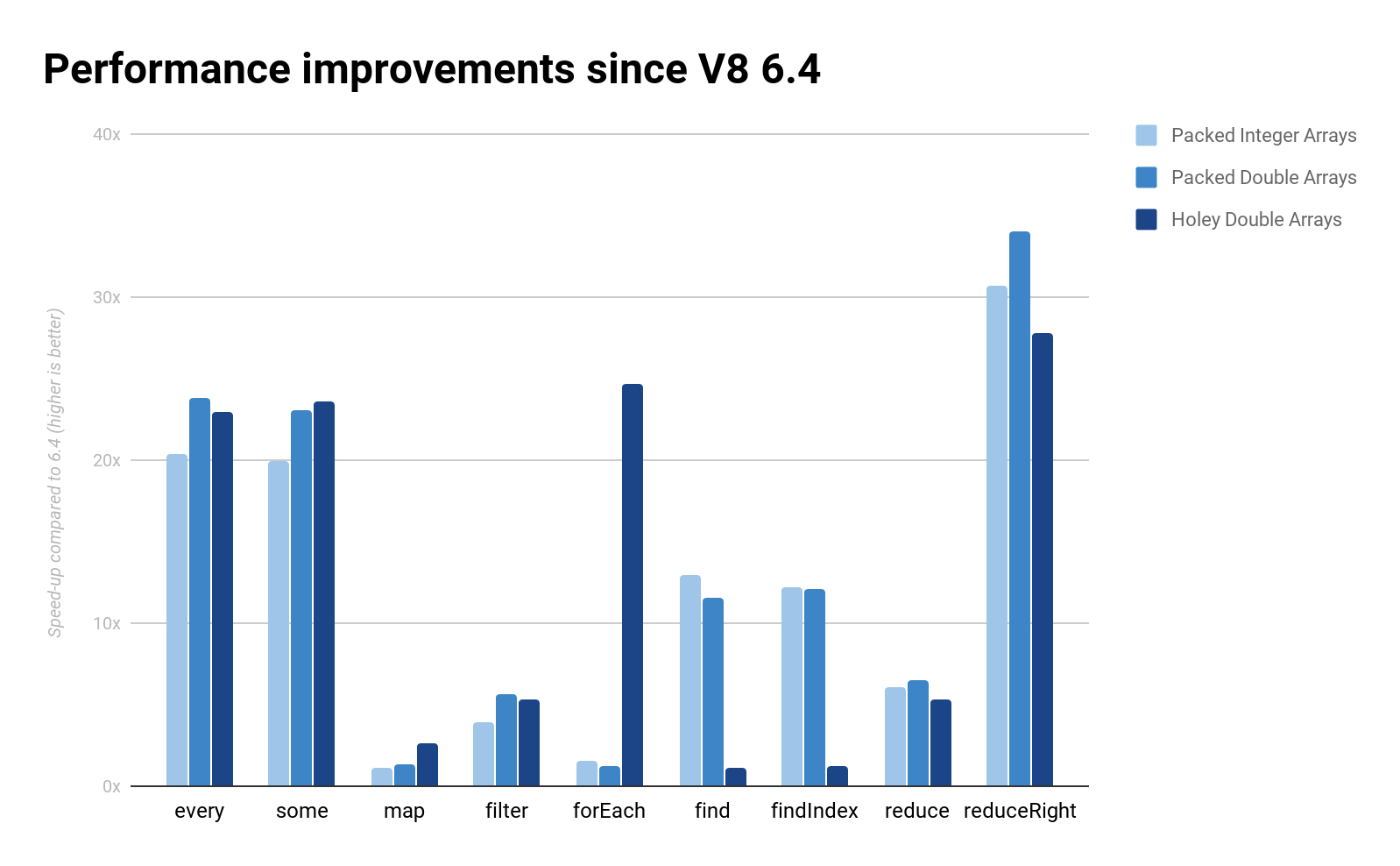
다음 이미지는 정수 배열, 이중 배열 및 구멍이있는 이중 배열로 분류 된 인라인 내장 함수에서 V8 v6.4와 비교하여 개선 델타를 보여줍니다. 시간은 밀리 초입니다.
V8 API
git log branch-heads/6.4..branch-heads/6.5 include/v8.hAPI 변경 목록을 얻으려면 사용하십시오 .
V8 체크 아웃git checkout -b 6.5 -t branch-heads/6.5 기능이있는 개발자 는 V8 v6.5의 새로운 기능을 실험 해 볼 수 있습니다 .
2018 년 1 월 29 일 월요일
해시 테이블 최적화 : 해시 코드 숨기기
ECMAScript 2015는 Map, Set, WeakSet 및 WeakMap과 같은 몇 가지 새로운 데이터 구조를 도입했습니다.이 구조는 모두 해시 테이블을 사용합니다. 이 게시물은 V8 v6.3 + 가 키를 해시 테이블에 저장하는 방법에 대한 최근 개선 사항을 자세히 설명합니다 .
해시 코드
해시 함수는 해시 테이블 내의 위치에 소정의 키를 매핑하는 데 사용된다. 해시 코드는 주어진 키를 통해이 해시 함수를 실행의 결과입니다.
V8에서 해시 코드는 개체 값과 별개로 임의의 숫자입니다. 그러므로 우리는 그것을 재 계산할 수 없습니다. 즉, 그것을 저장해야합니다.
이전에는 키로 사용 된 JavaScript 객체의 경우 해시 코드가 객체의 비공개 심볼로 저장되었습니다. V8의 비공개 기호는 a와 유사하지만 Symbol열거 할 수 없으며 자바 스크립트 사용자 공간으로 누출되지 않습니다.
function GetObjectHash(key) {
const hash = key[hashCodeSymbol];
if (IS_UNDEFINED(hash)) {
hash = (MathRandom() * 0x40000000) | 0;
if (hash === 0) hash = 1;
key[hashCodeSymbol] = hash;
}
return hash;
}
객체가 해시 테이블에 추가 될 때까지 해시 코드 필드에 대한 메모리를 예약 할 필요가 없었기 때문에이 작업이 효과적이었습니다. 해시 테이블에 새로운 비공개 심볼이 객체에 저장되었습니다.
V8은 IC 시스템을 사용하는 다른 속성 검색처럼 해시 코드 심볼 룩업을 최적화하여 해시 코드를 매우 빠르게 검색 할 수 있습니다. 이것은 키가 동일한 숨겨진 클래스를 가질 때 monomorphic IC 조회에 적합합니다 . 그러나 대부분의 실제 코드는이 패턴을 따르지 않으며 키에는 다른 숨겨진 클래스가 있기 때문에 해시 코드의 메가 모 픽 IC 조회 가 느려 집니다 .
개인 기호 방식의 또 다른 문제점 은 해시 코드를 저장할 때 키에서 숨겨진 클래스 전환 을 트리거한다는 점 입니다. 이로 인해 해시 코드 조회뿐만 아니라 키의 다른 속성 조회 및 최적화 된 코드의 최적화가 취소 된 빈약 한 다형성 코드가 생성되었습니다 .
JavaScript 객체 백업 저장소
JSObjectV8 의 JavaScript 객체 ( )는 요소를지지하는 요소에 대한 포인터를 저장하는 한 단어와 속성 저장 저장소에 대한 포인터를 저장하기위한 다른 단어라는 두 단어 (헤더 제외)를 사용합니다.
요소 배킹 저장소는 배열 인덱스 처럼 보이는 속성을 저장하는 데 사용 되지만 배킹 저장소 속성은 키가 문자열이나 심볼 인 속성을 저장하는 데 사용됩니다. 이 후원 상점에 대한 자세한 정보는 Camillo Bruni의 V8 블로그 게시물 을 참조하십시오 .
const x = {};
x[1] = 'bar'; // ← stored in elements
x['foo'] = 'bar'; // ← stored in properties
해시 코드 숨기기
해시 코드를 저장하는 가장 쉬운 방법은 JavaScript 객체의 크기를 한 단어 씩 늘리고 해시 코드를 객체에 직접 저장하는 것입니다. 그러나 이렇게하면 해시 테이블에 추가되지 않은 개체에 대한 메모리가 낭비됩니다. 대신 요소 저장소 또는 속성 저장소에 해시 코드를 저장하려고 할 수 있습니다.
요소 저장 저장소는 길이와 모든 요소를 포함하는 배열입니다. 예약 된 슬롯 (예 : 0 번째 인덱스)에 해시 코드를 저장하면 해시 테이블에서 키를 객체로 사용하지 않아도 메모리가 낭비됩니다.
부동산을지지하는 부동산을 살펴 봅시다. 속성 백업 저장소로 사용되는 데이터 구조에는 배열 및 사전의 두 가지 종류가 있습니다.
상한이없는 요소 배킹 스토어에 사용되는 배열과 달리, 배킹 스토어 속성에서 사용되는 배열의 상한값은 1022입니다. V8은 성능상의 이유로이 제한을 초과하는 사전을 사용하여 전환합니다. (나는 이것을 약간 단순화하고있다 - V8은 다른 경우에도 사전을 사용할 수 있지만 배열에 저장할 수있는 값의 수에 고정 된 상한이있다.)
따라서 저장소를 등록하는 속성에는 세 가지 상태가 있습니다.
- 비어 있음 (속성 없음)
- 배열 (최대 1022 개의 값을 저장할 수 있음)
- 사전
속성 저장소 저장소가 비어 있습니다.
빈 경우에는이 오프셋에 해시 코드를 직접 저장할 수 있습니다 JSObject.
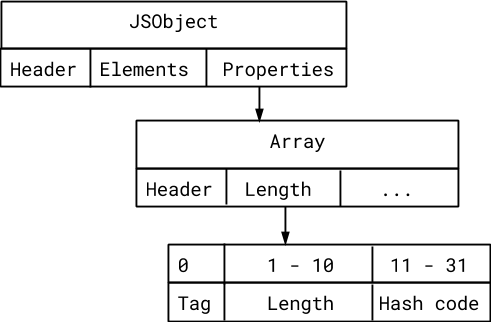
속성 저장소 저장소는 배열입니다.
V8은 Smi 와 같이 32 비트 시스템에서 2 31 미만의 정수를 unboxed로 나타냅니다 . Smi에서 최하위 비트는 포인터와 구별하기 위해 사용되는 태그이며 나머지 31 비트는 실제 정수 값을 보유합니다.
일반적으로 배열은 길이를 Smi로 저장합니다. 이 배열의 최대 용량이 1022라는 것을 알고 있기 때문에 길이를 저장하는 데 10 비트 만 있으면됩니다. 나머지 21 비트를 사용하여 해시 코드를 저장할 수 있습니다!
배킹 스토어 속성은 사전입니다.
사전의 경우, 사전 크기를 1 단어 씩 늘려 해시 코드를 사전 시작 부분의 전용 슬롯에 저장합니다. 비례 증가가 배열의 경우만큼 크지 않기 때문에이 경우 메모리를 낭비 할 가능성이 있습니다.

이러한 변경으로 해시 코드 조회는 더 이상 복잡한 JavaScript 속성 조회 기계를 거치지 않아도됩니다.
성능 향상
SixSpeed의 벤치 마크는지도와 설정, 그리고 ~ 500 % 개선 결과 이러한 변화의 성능을 추적합니다.

이 변경으로 인해 ARES6 의 기본 벤치 마크에서도 5 % 개선되었습니다 .
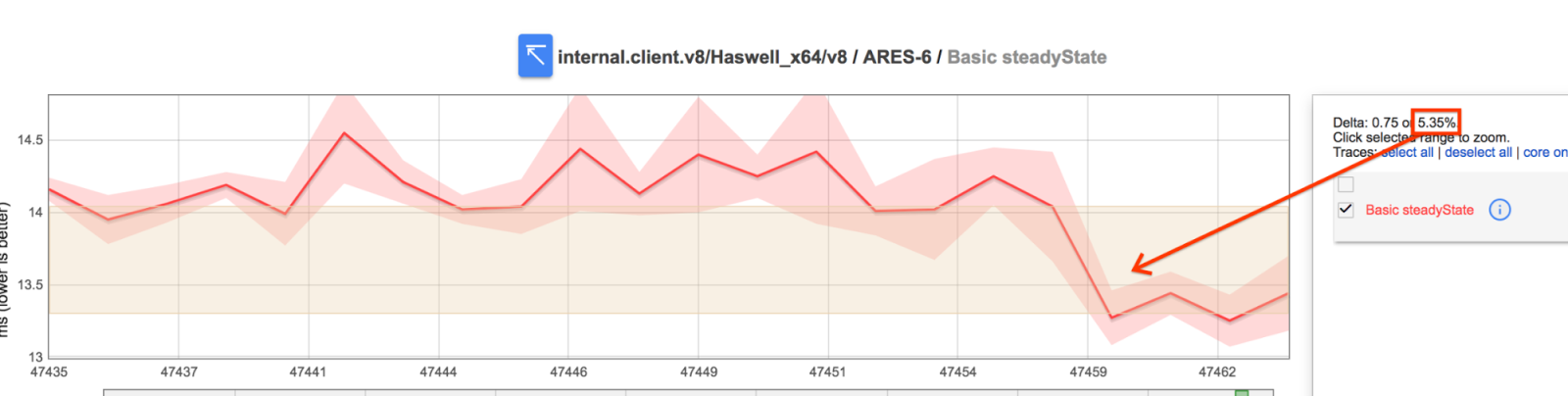
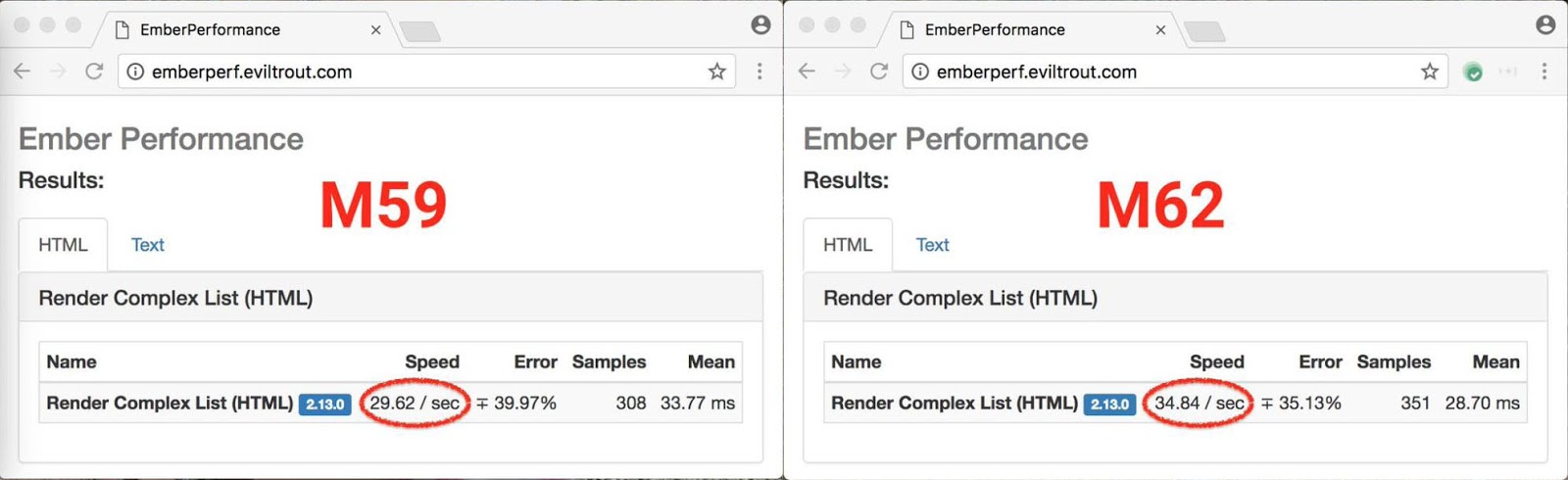
또한 Ember.js 를 테스트 하는 Emberperf 벤치 마크 제품군 의 벤치 마크 중 하나가 18 % 향상되었습니다 .
2018 년 1 월 24 일 수요일
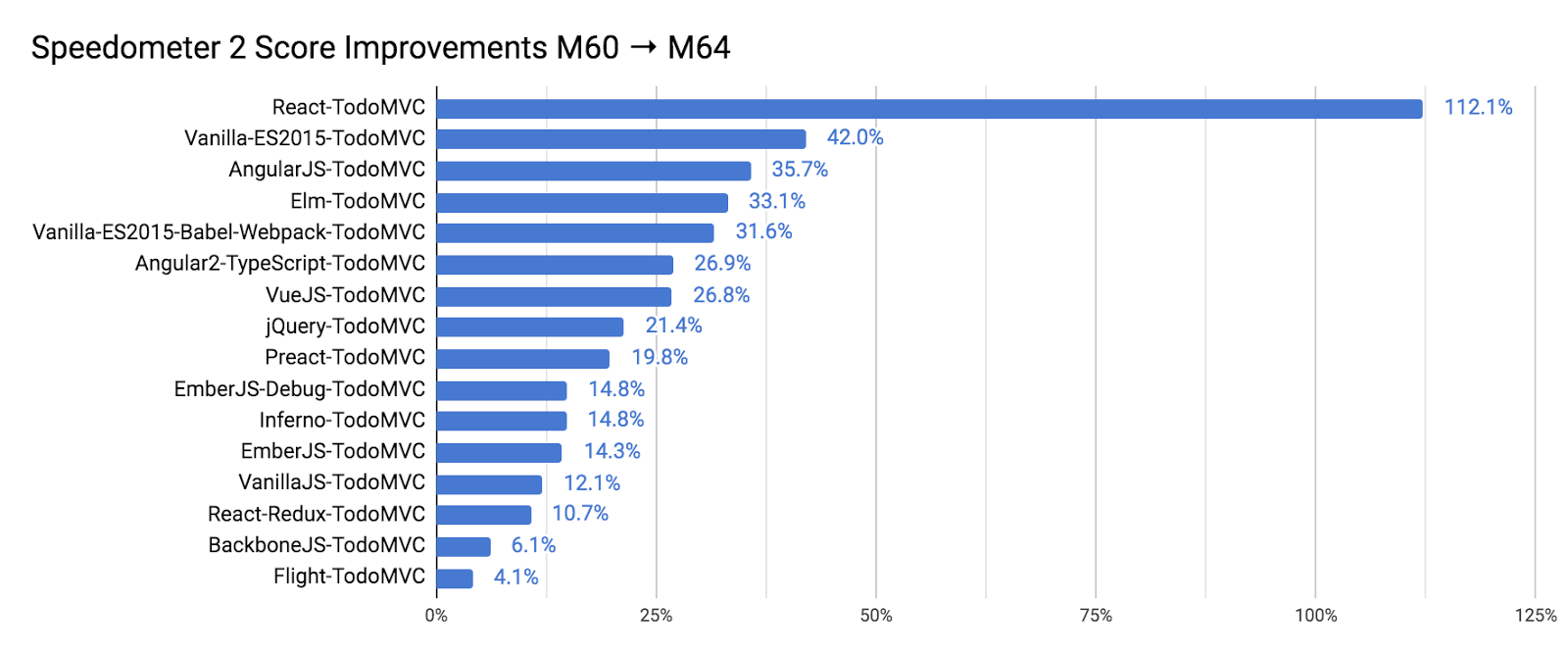
Chrome은 속도계 2.0을 환영합니다!


V8 릴리스 v6.4
6 주마다 릴리스 프로세스의 일부로 V8의 새 지점을 만듭니다 . 각 버전은 Chrome 베타 마일스톤 직전에 V8의 Git 마스터에서 분기됩니다. 오늘 우리는 최신 분기 인 V8 버전 6.4 를 발표하게되어 기쁩니다. V8 버전 은 몇 주 안에 Chrome 64 Stable과 함께 베타 버전으로 출시 될 예정입니다. V8 v6.4는 모든 종류의 개발자 지향적 인 상품으로 가득 차 있습니다. 이 게시물은 출시를 예상하여 일부 하이라이트에 대한 미리보기를 제공합니다.
속도
V8 v6.4 는instanceof 운영자 의 성능을 3.6 배 향상시킵니다 . 직접적인 결과로, V8의 Web Tooling Benchmark에 따르면 uglify-js 는 현재 15-20 % 더 빠릅니다 .
이 릴리스는 또한 성능 저하를 해결합니다 Function.prototype.bind. 예를 들어, 터보 팬 (TurboFan)은 이제 모든 단일 형태 호출을 일관되게 인라인합니다bind . 또한 TurboFan 은 다음과 같은 대신 콜백 패턴을 지원합니다 .
doSomething(callback, someObj);
이제 다음을 사용할 수 있습니다.
doSomething(callback.bind(someObj));
이 방법은 코드가 더 읽기 쉽고 여전히 동일한 성능을 얻습니다.
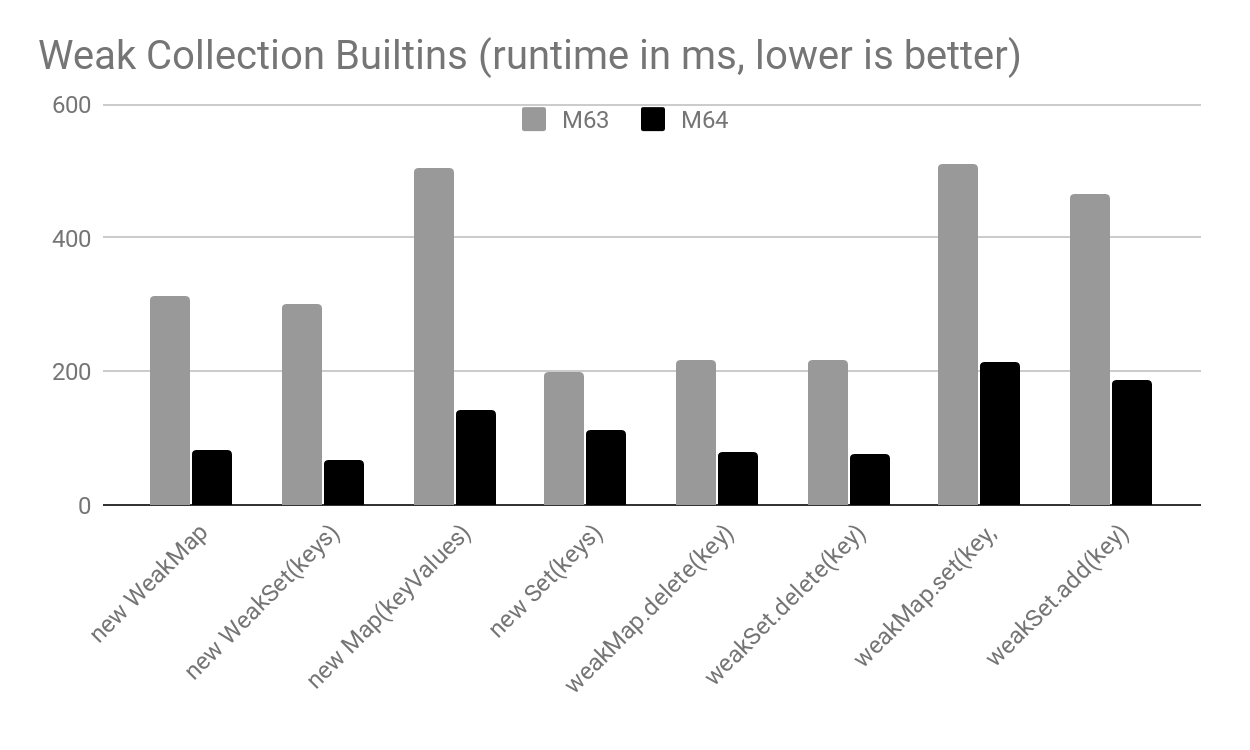
덕분에 피터 웡 의 최신 기여, WeakMap그리고 WeakSet지금 사용하여 구현된다 CodeStubAssembler을 전반적으로 최대 5 ×의 성능 향상의 결과.
V8 은 어레이 내장의 성능을 향상시키기 위한 노력의 일환 으로 Array.prototype.sliceCodeStubAssembler를 사용하여 성능을 4 배 향상 시켰 습니다. 또한, 호출 Array.prototype.map하고 Array.prototype.filter그들에게 손으로 쓴 버전과 경쟁력있는 성능 프로파일을 제공, 지금은 많은 경우에 인라인됩니다.
배열, 타입이 지정된 배열 및 문자열에서 범위를 벗어난로드를 만들기 위해 노력한 결과이 코딩 패턴 이 야생에서 사용되는 것을인지 한 후 ~ 10 배의 성능 저하가 발생하지 않았습니다 .
기억
V8의 내장 코드 오브젝트와 바이트 코드 핸들러는 스냅 샷에서 느리게 비 순차적으로 직렬화되므로 각 Isolate가 소비하는 메모리를 크게 줄일 수 있습니다. Chrome의 벤치 마크는 공통 사이트를 탐색 할 때 탭 당 수백 KB의 비용 절감 효과를 나타냅니다.
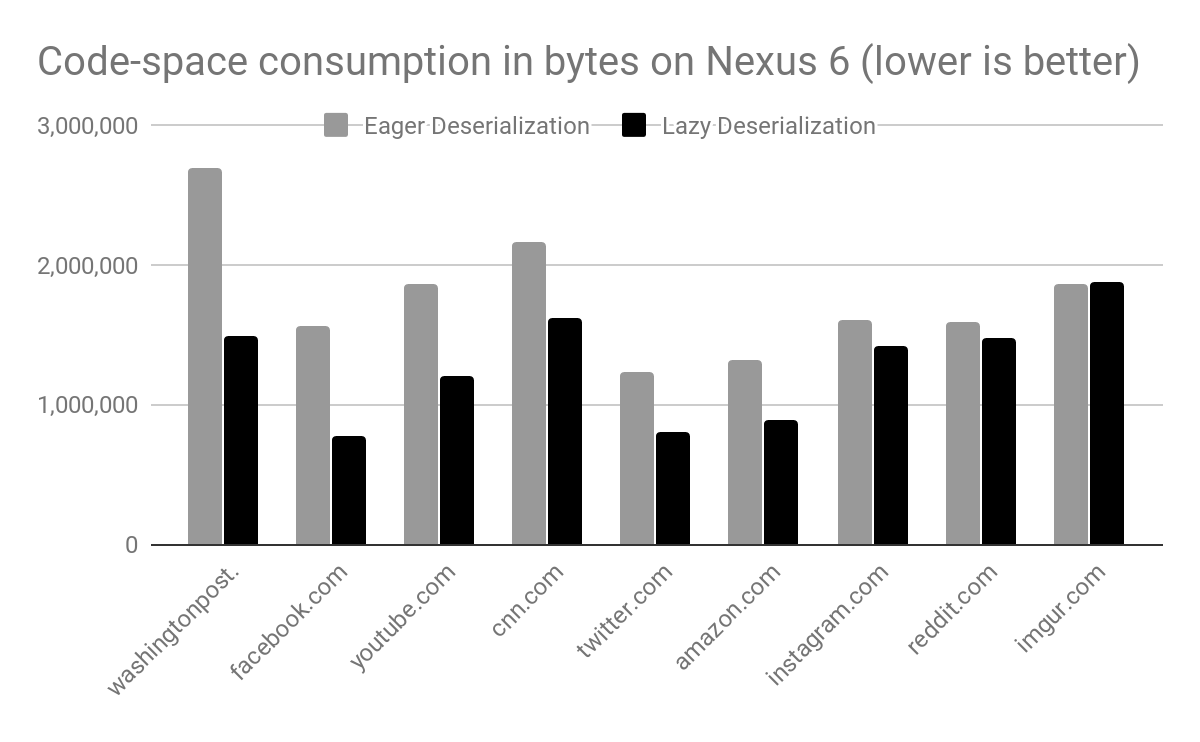
내년 초이 주제에 대한 전담 블로그 게시물을 찾아보십시오.
ECMAScript 언어 기능
이 V8 릴리스에는 2 개의 새로운 흥미 진진한 정규식 기능이 지원됩니다.
/u플래그 가있는 정규 표현식에서 기본적으로 유니 코드 속성 이스케이프 가 활성화됩니다.
const regexGreekSymbol = /\p{Script_Extensions=Greek}/u;
regexGreekSymbol.test('π');
// → true
이제 정규 표현식에서 명명 된 캡처 그룹 에 대한 지원 이 기본적으로 사용됩니다.
const pattern = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/u;
const result = pattern.exec('2017-12-15');
// result.groups.year === '2017'
// result.groups.month === '12'
// result.groups.day === '15'
이러한 기능에 대한 자세한 내용은 블로그 게시물의 다가오는 정규 표현식 기능에서 확인할 수 있습니다 .
Groupon 덕분에 V8 import.meta은 임베디드가 현재 모듈에 대한 호스트 별 메타 데이터를 노출 할 수있게합니다. 예를 들어 Chrome 64는을 (를) 통해 모듈 URL을 노출 import.meta.url하고 Chrome import.meta은 앞으로 더 많은 속성을 추가 할 계획 입니다.
국제화 형식 작성자가 작성한 문자열을 로컬 인식 형식으로 지원하기 위해 개발자는 Intl.NumberFormat.prototype.formatToParts()숫자를 형식 목록 및 형식으로 형식을 지정할 수 있습니다 . V8에서 이것을 구현 한 Igalia 에게 감사드립니다 !
V8 API
git log branch-heads/6.3..branch-heads/6.4 include/v8.hAPI 변경 목록을 얻으려면 사용하십시오 .
V8 체크 아웃git checkout -b 6.4 -t branch-heads/6.4 기능이있는 개발자 는 V8 v6.4의 새로운 기능을 실험 해 볼 수 있습니다 . 또는 Chrome의 베타 채널을 구독하고 곧 새로운 기능을 사용해 볼 수도 있습니다.
V8 팀에 의해 게시 됨
2017 년 12 월 13 일 수요일
자바 스크립트 코드 적용 범위
이게 뭐야?
코드 적용 범위는 응용 프로그램의 특정 부분이 실행되었는지 여부와 선택적 빈도에 대한 정보를 제공합니다. 일반적으로 테스트 스위트가 특정 코드베이스를 얼마나 철저하게 테스트 하는지를 결정하는 데 사용됩니다.
왜 그렇게 유용합니까?
자바 스크립트 개발자는 코드 커버리지가 유용 할 수있는 상황에 처한 경우가 종종 있습니다. 예를 들면 :
- 테스트 스위트의 품질에 관심이 있으십니까? 대규모 레거시 프로젝트 리팩토링? 코드 커버리지는 코드베이스의 어느 부분이 커버되는지 정확히 보여줄 수 있습니다.
- 코드베이스의 특정 부분에 도달했는지 빠르게 알고 싶습니까?
console.logfor-printfstyle 디버깅을 사용하거나 코드를 수동으로 실행 하는 대신 코드 적용 범위는 응용 프로그램의 어떤 부분이 실행되었는지에 대한 실시간 정보를 표시 할 수 있습니다. - 아니면 속도를 최적화하고 어떤 스포트에 집중할 지 알고 싶습니까? 실행 횟수는 핫 기능과 루프를 지적 할 수 있습니다.
V8의 자바 스크립트 코드 범위
올해 초 V8에 JavaScript 코드 커버리지에 대한 기본 지원을 추가했습니다. 버전 5.9의 초기 릴리스는 함수 세분성 (어떤 기능이 실행되었는지 보여주는)에서 적용 범위를 제공했으며, 나중에 6.2에서 블록 단위로 범위를 지원하도록 확장되었습니다 (마찬가지로 개별 표현식에 대해서도 마찬가지 임).
 |
| 함수 세분성 (왼쪽) 및 블록 세분성 (오른쪽) |
자바 스크립트 개발자를위한
현재 커버리지 정보에 액세스하는 두 가지 기본 방법이 있습니다. JavaScript 개발자의 경우 Chrome DevTools의 커버리지 탭 은 JS (및 CSS) 커버리지 비율을 노출하고 소스 패널에서 불량 코드를 강조 표시합니다.
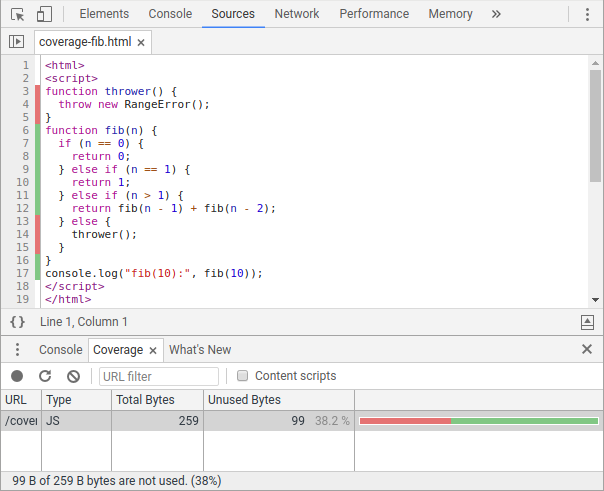 |
| DevTools Coverage 창에서 적용 범위를 차단하십시오. 뚜껑이있는 선은 녹색으로 강조 표시되며 빨간색으로 표시됩니다. |
Benjamin Coe 덕분에 V8의 코드 커버리지 정보를 인기있는 Istanbul.js 코드 커버리지 툴 에 통합 하는 작업 도 진행 중 입니다.
 |
| V8 범위 데이터를 기반으로 한 Istanbul.js 보고서입니다. |
임베디드 용
임 베더 및 프레임 워크 작성자는보다 유연하게 Inspector API에 직접 연결할 수 있습니다. V8은 두 가지 다른 커버리지 모드를 제공한다 :
Best-effort 서비스 범위 는 런타임 성능에 미치는 영향을 최소화하면서 서비스 범위 정보를 수집하지만 가비지 수집 (GC) 기능에서 데이터가 손실 될 수 있습니다.
정확한 범위 는 GC에 손실 된 데이터가 없음을 보장하며 사용자는 바이너리 적용 범위 정보 대신 실행 횟수를 수신하도록 선택할 수 있습니다. 오버 헤드가 증가하면 성능에 영향을 줄 수 있습니다 (자세한 내용은 다음 섹션 참조). 기능 범위 또는 블록 단위로 정확한 범위를 수집 할 수 있습니다.
정확한 적용 범위에 대한 Inspector API는 다음과 같습니다.
Profiler.startPreciseCoverage(callCount, detailed)선택적으로 콜 카운트 (바이너리 커버리지 대)와 블럭 입상 성 (기능 세분성)으로 커버리지 콜렉션을 가능하게한다.Profiler.takePreciseCoverage()수집 된 범위 정보를 연관된 실행 횟수와 함께 소스 범위 목록으로 반환합니다. 과Profiler.stopPreciseCoverage()수집을 비활성화하고 관련 데이터 구조를 해제합니다.
Inspector 프로토콜을 통한 대화는 다음과 같습니다.
// The embedder directs V8 to begin collecting precise coverage.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// Embedder requests coverage data (delta since last request).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// The reply contains collection of nested source ranges.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Block granularity.
"ranges": [ // An array of nested ranges.
{
"startOffset": 50, // Byte offset, inclusive.
"endOffset": 224, // Byte offset, exclusive.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// Finally, the embedder directs V8 to end collection and
// free related data structures.
{"id":37,"method":"Profiler.stopPreciseCoverage"}
마찬가지로 최선의 노력 범위는를 사용하여 검색 할 수 있습니다 Profiler.getBestEffortCoverage().
무대 뒤에서
이전 섹션에서 설명한 것처럼 V8은 최선의 노력과 정확한 적용이라는 두 가지 주요 코드 적용 모드를 지원합니다. 구현의 개요를 보려면 계속 읽으십시오.
최선의 노력 범위
최선형 및 정확한 커버 리지 모드는 다른 V8 메커니즘을 많이 재사용합니다. 그 중 첫 번째를 호출 카운터 라고합니다 . 함수가 V8의 Ignition 인터프리터를 통해 호출 될 때마다 함수의 피드백 벡터 에 대한 호출 카운터 를 증가시킨다 . 함수가 나중에 최적화되고 최적화 컴파일러를 통해 계층화됨에 따라이 카운터는 인라인 할 함수에 대한 인라인 결정을 안내하는 데 사용됩니다. 이제는 코드 적용 범위를보고하기 위해이 도구를 사용합니다.
두 번째 재사용 된 메커니즘은 기능의 소스 범위를 결정합니다. 코드 적용 범위를보고 할 때 호출 횟수는 소스 파일 내의 연관된 범위에 묶여 있어야합니다. 예를 들어 아래 예제에서 함수 f가 정확히 한 번 실행되었음을 보고 할 필요가있을 뿐만 아니라 f소스 범위가 1에서 시작하여 3에서 끝나는 것을보고해야합니다 .
function f() {
console.log('Hello World');
}
f();
다시 운이 좋았고 V8 내에서 기존 정보를 재사용 할 수있었습니다. 함수는 소스 코드 내의 시작 위치와 끝 위치를 이미 알고 Function.prototype.toString있으므로 적절한 하위 문자열을 추출하기 위해 소스 파일 내의 함수 위치를 알아야합니다.
최선의 노력 범위를 수집 할 때이 두 메커니즘은 간단히 묶여 있습니다. 먼저 모든 힙을 순회하여 모든 실제 기능을 찾습니다. 각각의 함수에 대해 호출 횟수 (함수에서 도달 할 수있는 피드백 벡터에 저장 됨)와 소스 범위 (편리하게 함수 자체에 저장 됨)를보고합니다.
통화량이 활성화되었는지 여부에 관계없이 호출 횟수가 유지되므로 최선형 통화권 범위는 런타임 오버 헤드를 유발하지 않습니다. 또한 전용 데이터 구조를 사용하지 않으므로 명시 적으로 활성화하거나 비활성화 할 필요가 없습니다.
그러면 왜이 모드가 최선 노력이라고 불리는가, 그 한계는 무엇인가? 범위를 벗어난 함수는 가비지 컬렉터에 의해 해제 될 수 있습니다. 이것은 관련된 호출 횟수가 손실된다는 것을 의미하며, 실제로 이러한 함수가 존재한다는 사실을 완전히 잊어 버립니다. Ergo 'best-effort': 최선을 다했지만 수집 된 보험 정보가 불완전 할 수 있습니다.
정확한 범위 (함수 단위)
최선형 모드와 달리 정확한 범위는 제공된 범위 정보가 완전 함을 보장합니다. 이를 달성하기 위해 정확한 커버리지가 활성화되면 V8의 루트 세트에 모든 피드백 벡터를 추가하여 GC에 의한 수집을 방지합니다. 이렇게하면 정보가 손실되지 않게되지만 객체를 인위적으로 유지하여 메모리 소비를 증가시킵니다.
정확한 커버리지 모드는 또한 실행 카운트를 제공 할 수있다. 이는 정확한 커버리지 구현에 또 다른 주름을 일으킨다. 호출 카운터는 V8의 인터프리터를 통해 함수가 호출 될 때마다 증가되며 함수가 뜨거워 질 때 계층화되고 최적화 될 수 있다는 점을 상기하십시오. 그러나 최적화 된 함수는 더 이상 호출 카운터를 증가시키지 않으므로보고 된 실행 횟수가 정확하도록 최적화 컴파일러를 비활성화해야합니다.
정확한 범위 (블록 세분성)
블록 단위 범위는 개별 표현 수준까지 올바른 범위를보고해야합니다. 예를 들어, 다음 코드에서 블록 범위 else는 조건부 표현식 의 분기 : c가 실행되지 않는다는 것을 감지 할 수있는 반면 함수 세분성 범위는 함수 f가 전체적으로 포함 된다는 것을 알 수 있습니다.
function f(a) {
return a ? b : c;
}
f(true);
이전 섹션에서 이미 V8에서 사용할 수있는 함수 호출 횟수와 소스 범위가 있음을 상기 할 수 있습니다. 불행하게도 이것은 블록 범위에 해당하지 않으며 실행 횟수와 해당 소스 범위를 수집하는 새로운 메커니즘을 구현해야했습니다.
첫 번째 측면은 소스 범위입니다. 특정 블록에 대한 실행 횟수가 있다고 가정 할 때 소스 코드의 섹션에 어떻게 매핑 할 수 있습니까? 이를 위해 소스 파일을 파싱하는 동안 관련 위치를 수집해야합니다. 적용 범위를 차단하기 전에 V8은 이미 어느 정도 이것을 수행했습니다. 한 가지 예가 Function.prototype.toString위에서 설명한 기능 범위의 수집입니다 . 또 다른 하나는 소스 위치가 Error 객체에 대한 백 트레이스를 생성하는 데 사용된다는 것입니다. 그러나 이들 중 어느 것도 블록 수용 범위를 지원하기에 충분하지 않습니다. 전자는 함수에만 사용할 수 있으며 후자는 소스 범위가 아닌 위치 (예 : - 명령문 의 if토큰 위치) 만 저장 합니다.ifelse
따라서 소스 범위를 수집하기 위해 파서를 확장해야했습니다. 설명하기 위해, 고려 if- else: 문을
if (cond) {
/* Then branch. */
} else {
/* Else branch. */
}
블록 적용 범위가 활성화되면 and의 분기 범위를 수집 하여 파싱 된 AST 노드 와 연결합니다 . 다른 관련 언어 구조도 마찬가지입니다.thenelseIfStatement
파싱하는 동안 소스 범위 수집을 수집 한 후 두 번째 측면은 런타임에 실행 횟수를 추적합니다. 이것은 생성 된 바이트 코드 배열 내의 전략적 위치에 새로운 전용 바이트 코드를 삽입함으로써 행해진 다 IncBlockCounter. 런타임시 IncBlockCounter바이트 코드 처리기 는 적절한 카운터 (함수 개체를 통해 도달 가능)를 단순히 증가시킵니다 .
의 위의 예에서 if- else문, 같은 바이트 코드는 세 지점에 삽입 될 것이다 :의 몸에 직전 then분기의 몸에 이전 else지점, 즉시 후 if- else문 (예 : 연속 카운터는 가능성으로 인해 필요 지사 내 비 로컬 제어).
마지막으로,보고 입상 범위는 기능 입상보고와 유사하게 작동합니다. 그러나 호출 수 (피드백 벡터) 외에도 흥미로운 소스 범위 의 수집을 블록 수 (함수에서 중단되는 보조 데이터 구조에 저장 됨)와 함께 보고합니다 .
'개발 > Javascript' 카테고리의 다른 글
| 자바스크립트 이벤트 (0) | 2018.04.18 |
|---|---|
| [번역] 자바스크립트 스코프와 클로저(JavaScript Scope and Closures) (0) | 2018.04.05 |
| 이벤트(Events) (0) | 2018.03.11 |
| 억세서(Accessors) (0) | 2018.03.11 |
| 명명규칙(Naming Conventions) (0) | 2018.03.11 |